Project Overview
This project focuses on the automatic estimation of sheep count in video footage, utilizing a 3D Convolutional Neural Network (CNN) combined with a recurrent layer to analyze both spatial and temporal patterns in short video clips.
Methodology
There was lack of publicly available, well-labeled datasets specifically suited for the task of sheep counting in videos. Most datasets either focused on classification or segmentation, rather than object count in temporal sequences. As a result, a custom dataset had to be manually prepared.
Then a custom dataset was created by processing videos of sheep into 16-frame clips, which were then resized to 128x128 pixels and normalized. Each clip was labeled with the ground-truth sheep count.
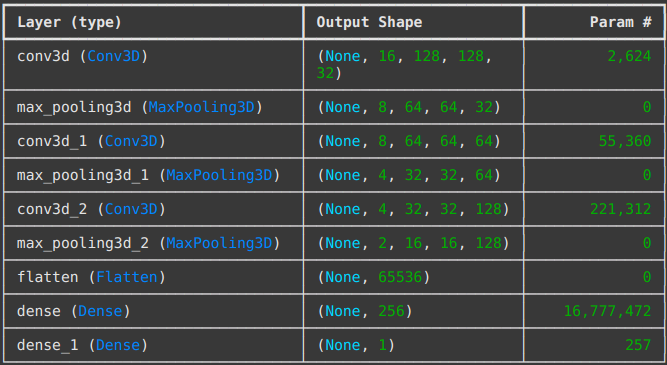
The model architecture is a 3D Convolutional Neural Network (3D CNN) designed to extract visual patterns (spatial features) and movement (temporal features) simultaneously. The architecture consists of three 3D convolutional blocks followed by dense layers, culminating in a single output neuron that predicts the sheep count. The model was trained using the Adam optimizer and Mean Squared Error loss function.
Technologies Used
Python
TensorFlow/Keras
OpenCV
NumPy
Google Colab
Results & Achievements
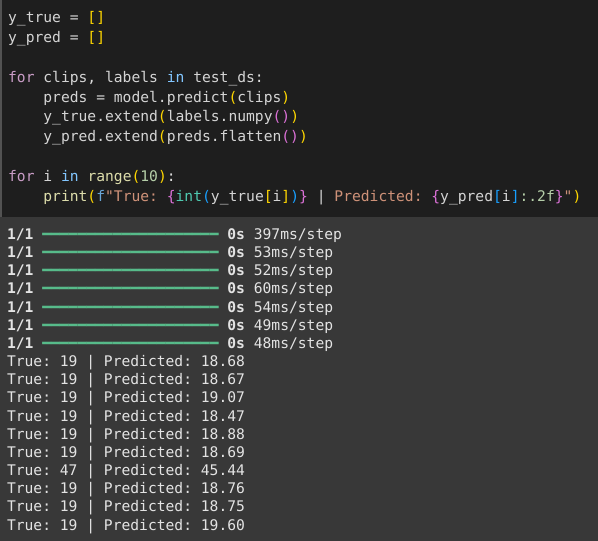
The trained model demonstrated reasonable performance and generalized well when tested on unseen video clips from various sources. Test results show the model's accuracy, with predictions closely matching the actual counts. For example, for a clip with 19 sheep, the model predicted counts such as 18.68 and 19.07, and for a clip with 47 sheep, it predicted 45.44.
Links & Documents
Report
Github Page